MongoDB 복제 구성을 docker기반에서 테스트한 내용을 공유하겠습니다.
대부분은 구글 검색을 통해서 찾은 내용이고, 직접 테스트한 내용입니다.
1. MongoDB 의 복제
MongoDB 의 Replica set 은 동일한 데이터 세트를 유지 관리하는 mongod 인스턴스 그룹이다. Replica set 에는 여러 데이터 베어링 노드와 선택적으로 하나의 중재자(abiter) 노드가 포함 되게 된다.
데이터 베어링 노드 중 하나의 구성원만 Primary(기본) 노드가 되며 다른 노드는 Secondary 노드가 된다.
단일 Replica set 구조에서는 별도의 관리용 컴포넌트가 필요하지는 않지만, 단일 노드(Standalone) 에 비해서 추가로 MongoDB 서버가 필요 하다.
Replica set은 특정 서버에 장애가 발생했을 때 자동 복구를 위한 최소 단위이므로 자동 복구가 필요하다면 항상 Replica set 형태로 MongoDB 를 배포를 해야 한다.
MongoDB의 고가용성은 Replica set 내부에서 처리된다. 샤딩된 클러스터 구조뿐만 아니라 단일 Replica set 에서 고가용성이 처리 된다.
고가용성을 위해서 MongoDB Replica set 의 각 멤버는 서로 다른 멤버가 살아 있는지 계속 확인 메세지를 주고 받게 되는데, 이를 Heartbeat 메세지라고 한다.
만약 Primary 노드(멤버)가 통신이 되지 않는다면 다른 멤버들이 새로운 Primary 멤버를 선출해서 서비스가 계속 될 수 있도록 처리를 하게 된다.
이렇게 새로운 Primary 멤버 선출 과정에서의 MongoDB의 샤딩이나 MongoDB 컨피그 서버와는 무관하게 Replica set 내에서 처리되게 된다.
복제의 또 다른 목적으로는 부하 분산이 있다. 데이터 조회 쿼리의 로드를 분산하여 사용할 수 있다.
MongoDB Replica set 에서 고가용성을 위해 많은 멤버를 투입할 필요는 없다.
일반적으로 고가용성만을 위한 멤버 구성으로 3대 정도의 서버로 구성하는 것이 일반적이며, 만약 데이터 조회 쿼리가 아주 많거나 부하가 있는 서비스에서는 멤버를 더 추가하는 것을 고려 해볼 수 있다.
MongoDB 의 Replica set 에서 쓰기 쿼리를 처리 할 수 있는 것은 오직 Primary 노드(멤버) 만 가능 하다. 그래서 멤버를 더 많이 추가 한다고 해도 쓰기 쿼리에 대한 확장 또는 부하 분산은 할수 없다. 하지만 멤버가 늘어 난 만큼 읽기 쿼리는 부하 분산 할 수 있다.
MongoDB 드라이버를 통해 단일 노드(Standalone) 로 접속시 MongoDB 서버로 접속을 하지만, Replica set 에 접속 할 때는 Replica set 옵션을 사용해야 하며, Replica set 에 접속하여 읽기 쿼리는 Primary 에서 수행이 기본 설정이다.
MongoDB드라이버에서 접속시 Read Preference 옵션을 통해서 해당 부분을 제어 할 수 있다.
2. Replica set 구성 형태
MongoDB 에서도 다른 RDBMS의 Replication 과 동일(유사) 하게 Primary node 에서 모든 쓰기 작업을 수행하게 된다.
그리고 기본적으로는 읽기 작업 또한 Primary 노드 에서 수행 된다.

위의 이미지와 같이 하나의 Replica set 은 항상 하나의 Primary 노드와 1개 이상의 Secondary 노드로 구성되게 된다.
데이터의 모든 변경 사항은 oplog 에 기록을 하게 되며, Secondary 노드는 Primary 노드의 oplog 를 전달받아서 데이터 동기화를 진행 하게 된다.
Primary 와 Secondary 노드 서로간의 heartbeat 을 통한 상태 체크가 이루어지며, Primary 노드를 사용할 수 없는 경우(장애나 네트워크 이슈 등) 적격한 Seconadry 노드는 새로운 Primary 노드를 선택하기 위한 투표를 개최한다.
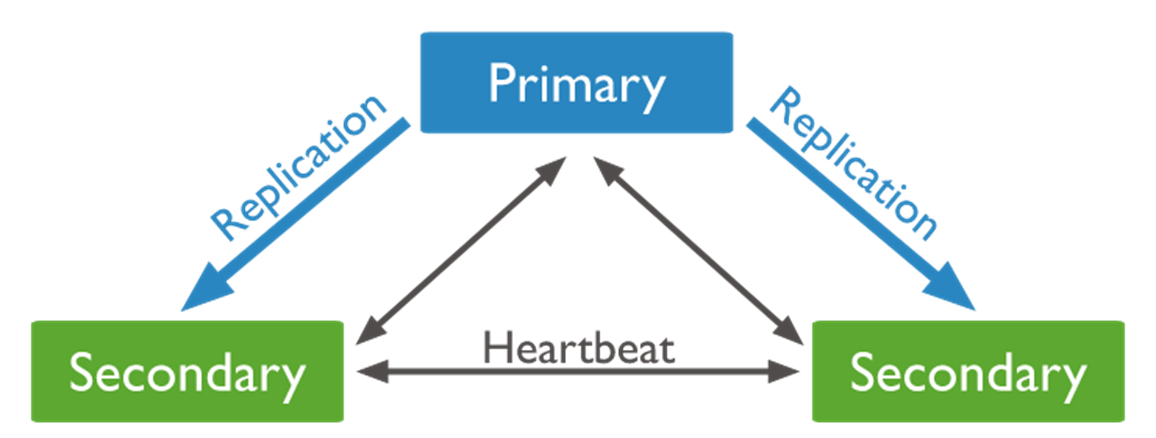
투표를 통해서 Primary 노드가 결정하므로 가능한 홀수 개의 노드로 구성하는 것이 좋다.
짝수개의 노드로 Replica set 을 구성할 수 있지만 실제 Replica set의 가용성은 홀수 개의 노드로 구성 했을 때와 다르지 않아서 서버의 낭비로 이어질수도 있다.
Replica set 을 3대 서버로 구축하는 것도 사용에 따라서 서버 낭비라고 생각 될수도 있다. 이럴 경우 Arbiter 모드의 MongoDB 를 사용할 수 있으며 이 Arbiter 모드의 MongoDB는 Primary 노드가 불능일 때 Primary 노드의 선출을 위한 투표에만 참여하게 된다(Vote Only)
그래서 Arbiter 는 디스크에 데이터를 저장 하지 않으며, Primary 노드로 부터 데이터를 받지 않기 때문에 서버의 사양도 다른 Primary 나 Secondary 노드 처럼 고사양일 필요는 없으며 하나의 Replica set 에는 여러개의 Arbiter 가 존재할 수 있지만 실제 정상적인 상황에서는 하나 이상의 Arbiter 는 필요하지 않다.
그리고 중요한 점은 실제 운영 환경에서는 arbiter 모드의 MongoDB를 Primary 나 Secondary 멤버와 같은 물리적으로 같은 서버에서 사용하지 않는 것이 중요 하다.

'DB' 카테고리의 다른 글
| Oracle to PostgreSQL 쿼리 변환 (0) | 2023.04.10 |
|---|---|
| Postgresql pgpool을 활용한 클러스터 명령어 및 docker-compose (0) | 2023.04.10 |
| Postgresql pgpool을 활용한 클러스터링 (0) | 2023.04.10 |
| MongoDB Replicaset 구성 명령어 (0) | 2023.04.07 |
| PostgreSql postgis 쿼리 (0) | 2023.04.07 |


